 Maximilian Filtenborg
Maximilian Filtenborg
Bedrijven genereren enorme hoeveelheden informatie in een ongekend tempo. Organisaties hebben om inzichten te vergaren een robuuste en flexibele data-infrastructuur nodig, het datawarehouse.
Datawarehouses: de backbone van moderne data-analytics. Dit uitgebreide artikel zal dieper ingaan op de essentie van datawarehouses, waarbij hun definitie, architectuur, voordelen en best practices worden onderzocht. Of je nu een data-enthousiasteling bent of een zakelijke professional die data wil benutten voor strategisch voordeel, deze gids geeft je de kennis om het ware potentieel van datawarehouses te benutten.
Dit artikel is opgedeeld in 3 delen:
Aan het einde heb je de basiskennis van wat een datawarehouse is, hoe het onder de motorkap werkt en hoe de prijsstructuur van de belangrijkste cloud datawarehouse-aanbiedingen is opgebouwd.
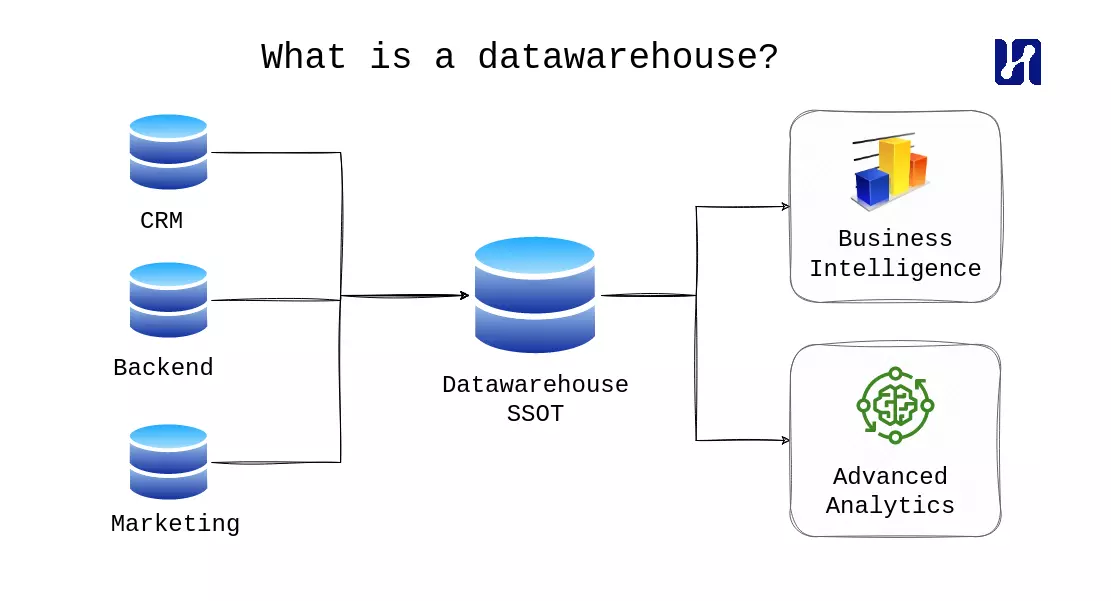
Een datawarehouse is een gecentraliseerd opslagsysteem dat gegevens integreert vanuit verschillende bronnen binnen een organisatie. Het fungeert als een geconsolideerde en gestructureerde oplossing voor gegevensopslag, waarmee bedrijven hun gegevens kunnen harmoniseren en organiseren in een consistente indeling. In tegenstelling tot traditionele transactionele databases, die zijn geoptimaliseerd voor dagelijkse operaties, zijn datawarehouses ontworpen om analytische vragen te ondersteunen en een alomvattend beeld te bieden van het gegevenslandschap van de organisatie.
The world’s most valuable resource is no longer oil, but data.
Bron: The Economist
Organisaties in verschillende sectoren erkennen de enorme waarde van data in het huidige digitale landschap. Data-gedreven besluitvorming is een strategische noodzaak geworden voor bedrijven die streven naar een concurrentievoordeel. De enorme hoeveelheid, variëteit en snelheid van gegenereerde data kunnen echter aanzienlijke uitdagingen met zich meebrengen. Datawarehouses spelen in op deze behoefte door robuuste oplossingen te bieden voor het beheren en analyseren van grote hoeveelheden gegevens binnen een organisatie. Door gegevens te consolideren tot één bron van waarheid stellen datawarehouses bedrijven in staat om efficiënte gegevensbeheer, integratie en analyse mogelijk te maken, waardoor ze betekenisvolle inzichten kunnen verkrijgen en op data gebaseerde beslissingen kunnen nemen.
Datawarehouses faciliteren krachtige analysemogelijkheden door een gestructureerde en geoptimaliseerde omgeving te bieden voor vragen en rapportages. Met de mogelijkheid om historische gegevens op te slaan, stellen datawarehouses organisaties in staat om trendanalyse uit te voeren, patronen te identificeren en geïnformeerde voorspellingen te doen. Bovendien bieden datawarehouses een holistisch beeld van de bedrijfsvoering door gegevens uit verschillende bronnen te integreren, zoals operationele systemen, CRM-platforms, marketingdatabases en meer. Dit faciliteert cross-functionele analyse en stelt belanghebbenden in staat inzichten te halen uit verschillende domeinen van gegevens.
Door een enkele bron van waarheid (SSOT) vast te stellen en een goed geschikte analytische database te ontwikkelen, zet je de eerste stap naar het mogelijk maken van self-service business intelligence (BI). Het is cruciaal om te voorkomen dat rapporten worden gemaakt op een onbetrouwbare basis, omdat dit vaak leidt tot onbruikbare resultaten. Met een solide basis kun je de drempels voor iedereen in je organisatie om toegang te krijgen tot en gebruik te maken van de beschikbare gegevens aanzienlijk verlagen.
Bovendien biedt een datawarehouse de mogelijkheid voor historische analyse en trendidentificatie. Operationele databases richten zich doorgaans op het bijwerken van records, wat uitdagingen kan opleveren bij het analyseren van historische gegevens. Het temporair opslaan van gegevens met gebeurtenissen stelt je in staat om wijzigingen effectief bij te houden. Je datawarehouse dient als een ideaal platform voor het opbouwen van een temporale weergave van je gegevens, waardoor historische analyse en trendidentificatie gemakkelijk worden.
Bij het vaststellen van een SSOT is het essentieel om rekening te houden met gegevenstoegangsbeheer. Rolgebaseerd toegangsbeheer (RBAC) en rol-erfenis spelen een vitale rol op dit gebied, en veel datawarehouses bieden ondersteuning voor deze functies in verschillende vormen. Door RBAC te benutten, kun je een rolhiërarchie creëren met privileges-erfenis die de organisatiestructuur weerspiegelt. Dit stelt je in staat om data-democratisering en intuïtieve gegevenstoegang te implementeren en beheren, terwijl je de noodzakelijke beveiligingsmaatregelen handhaaft.
Abbonneer op onze nieuwsbrief en ontvang deskundige inzichten, bruikbare strategieën en verhalen uit de echte wereld die u zullen begeleiden naar het behalen van datagedreven succes.
Wij geven om de bescherming van uw gegevens. Lees onze Privacy Policy.
Om het volledige potentieel van AI binnen je organisatie te benutten, speelt een datawarehouse (of georganiseerd datameer) een cruciale rol door AI-toepassingen op vier kritieke manieren mogelijk te maken:
Datawarehouses spelen een cruciale rol in het data-gedreven landschap van vandaag, waardoor organisaties waardevolle inzichten kunnen verkrijgen, operationele efficiëntie kunnen verbeteren, markttrends kunnen identificeren, groeikansen kunnen grijpen, gegevens kunnen democratiseren en hun AI-capaciteiten kunnen vergroten. Door datawarehouses effectief te benutten, kunnen bedrijven de kracht van data gebruiken om succes te stimuleren.
In dit gedeelte gaan we dieper in op de architectuur van datawarehouses en verkennen we hun interne werking.
Terwijl operationele databases zijn ontworpen voor online transactieverwerking (OLTP), zijn datawarehouses gericht op online analytische verwerking (OLAP). Een belangrijk verschil van OLAP-databases tegenover OLTP-databases is het opslagmechanisme, OLAP databases maken vaak gebruikmaken van kolomgebaseerde opslag in plaats van rijgebaseerde opslag. Het is belangrijk om de juiste tool te kiezen voor de taak, omdat OLAP-databases niet goed geschikt zijn voor het verwerken van OLTP-werkbelastingen. Deze keuze heeft invloed op het proces van het laden van gegevens in het datawarehouse.
Een veelgebruikte aanpak is de scheiding van rekenkracht en opslag in datawarehousing. Deze aanpak maakt onafhankelijke schaling van rekenkracht en opslag mogelijk, waardoor organisaties alleen betalen voor wat ze gebruiken, vooral in cloudgebaseerde datawarehouses. Door gegevens naar de rekenkracht te verplaatsen in plaats van andersom, excelleren cloud-datawarehouses en lakehouse-technologieën in het omgaan met analytische systemen waarbij het vermogen om grote hoeveelheden gegevens te verwerken prioriteit heeft boven latentieproblemen. De discussie is echter nog niet afgerond; een populaire technologie is DuckDB, een in-process database geschikt voor analytische queries. DuckDB kan worden gezien als de SQLite van OLAP. Hoewel het misschien niet je typische datawarehouse is, verdient het wel vermelding.
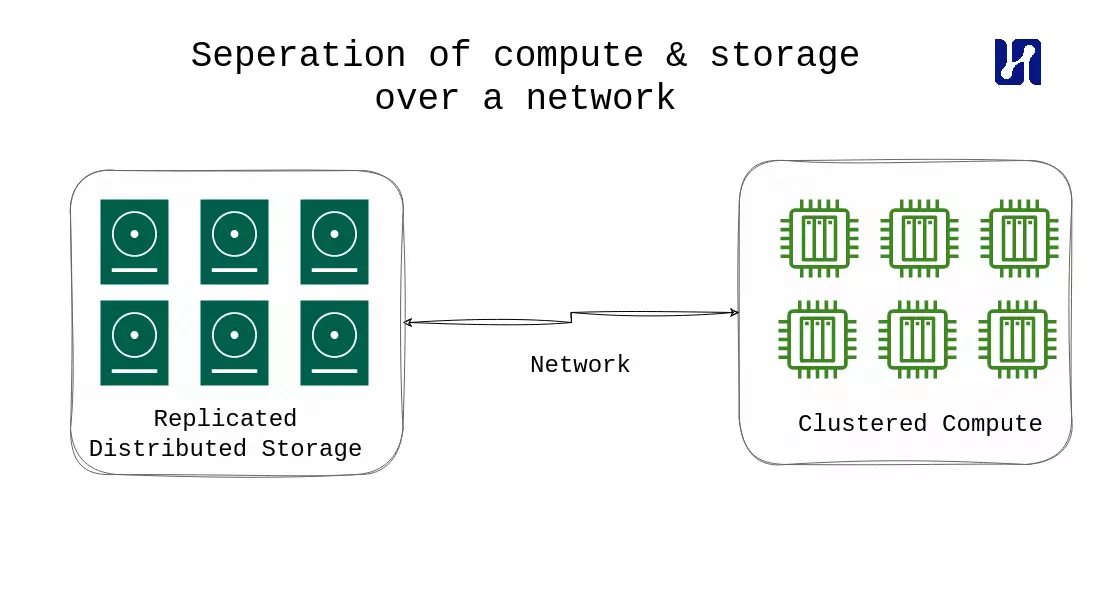
Datawarehouses en het opkomende concept van een “lake house” slaan meestal alle gegevens op één centrale locatie op. Deze centrale locatie is vaak een cloud-opslagplaats, zoals AWS S3, die fungeert als een robuuste opslaghub. Gegevens worden geladen vanuit het datameer naar het datawarehouse, waarbij gebruik wordt gemaakt van de eenvoud en kracht van cloudopslag. Deze opzet is snel populair geworden, omdat cloudopslag zeer robuust en schaalbaar is.
Veel mensen raken in de war door alle buzzwords in de datawereld tegenwoordig. We maken vaak de grap dat een datalake gewoon een map met bestanden in de cloud is.
Het verkrijgen van betrouwbare en hoogwaardige gegevens is van cruciaal belang om het volledige potentieel van analyses te benutten. Door een goed gedefinieerd proces voor gegevensreiniging en modellering binnen uw datawarehouse te implementeren, kunt u een Single Source of Truth (SSOT) vaststellen die gegevensintegriteit en bruikbaarheid waarborgt.
Dit is hoe dit proces uw analysemogelijkheden verbetert:
Om een datawarehouse te creëren, is de eerste stap het extraheren van gegevens uit verschillende bronnen binnen uw organisatie. Traditioneel gezien omvatte dit proces het handmatig coderen van Python- en shell-scripts. Er zijn echter nu tal van tools beschikbaar om deze taak te vereenvoudigen en te stroomlijnen. Een belangrijke verandering in het datalandschap is de verschuiving van ETL (Extract, Transform, Load) naar ELT (Extract, Load, Transform). We hebben dit onderwerp ook behandeld in onze blogpost over de Moderne Data Stack, die je hier kunt vinden.
Er zijn over het algemeen twee benaderingen voor gegevensextractie en laden. De eerste benadering is het gebruik van tools voor gegevensinname zoals Airbyte en Meltano, die rechtstreeks laden van gegevens in het datawarehouse mogelijk maken. Deze tools zijn efficiënt voor het snel inladen van verschillende soorten gegevens, zoals Google Analytics-trackinggegevens en Salesforce CRM-gegevens. De tweede benadering omvat het extraheren van gegevens naar een cloud-opslagplaats (vaak aangeduid als een datalake) via alternatieve middelen om deze vervolgens in het datawarehouse te laden met behulp van een native loader. Deze benadering biedt vaak de beste prestatiekenmerken. Bij het ontwerpen van uw ETL-proces is een belangrijk aspect om rekening mee te houden dat datawarehouses niet zijn geoptimaliseerd voor online transactieverwerking (OLTP). Dit betekent dat het laden van gegevens in batches meestal sneller, kosteneffectiever is en de algehele prestaties op de lange termijn verbetert.
Nadat de gegevens zijn geladen in het datawarehouse, is de volgende stap gegevenstransformatie. In het ELT-paradigma wordt deze transformatie meestal in fasen uitgevoerd. Op dit moment kunnen we optimaal profiteren van de mogelijkheden van het datawarehouse en tools zoals dbt gebruiken om het gegevenstransformatieproces te ondersteunen. Dbt biedt verschillende voordelen. Ten eerste stelt het ons in staat om aangepaste code te vermijden door gebruik te maken van de expressieve kracht van SQL. Daarnaast kunnen we profiteren van de schaalbaarheid van het datawarehouse, waardoor de noodzaak om een Apache Spark-cluster of vergelijkbare infrastructuur op te zetten, wordt geëlimineerd. Ten slotte biedt dbt voordelen zoals het behandelen van SQL meer als code, waardoor we herbruikbare SQL-query’s kunnen schrijven en het implementeren van tests voor onze transformaties wordt vergemakkelijkt.
Na een grondige verkenning van de details van de datawarehouse-architectuur, zullen we nu de beschikbare prijsopties voor cloud datawarehouses verkennen. Het begrijpen en evalueren van de kosten en return on investment (ROI) is cruciaal voordat u begint met het bouwen van een cloud datawarehouse.

In dit gedeelte zullen we de prijsopties van enkele belangrijke cloud datawarehouse providers vergelijken. Onze vergelijking omvat Google BigQuery, AWS Redshift, Azure Synapse Analytics en de cloud-agnostische datawarehouse-oplossing, Snowflake.
Let op dat dit gedeelte geen betrekking zal hebben op OLAP-databases die zijn ontworpen voor realtime analyses, zoals Apache Druid, ClickHouse en SingleStore. Deze databases dienen een ander gebruiksdoel, wat we in een apart artikel zullen belichten.
Als je meteen naar de conclusie wilt gaan wat betreft de prijsstelling, hebben we aan het einde een uitgebreide tabel verstrekt.
Elke databaseprovider ondersteunt meerdere prijsopties. Als we ze zouden categoriseren, zijn de belangrijkste opties de op capaciteit gebaseerde prijsstelling en de serverloze prijsstelling. Bij op capaciteit gebaseerde prijzen betaal je voor het draaien van een datawarehouse met bepaalde specificaties, die kunnen worden gekoppeld aan een bepaald aantal vCPUs en RAM dat je datawarehouse heeft wat betreft rekenkracht. De koppeling is nodig omdat elke cloudprovider zijn eigen manier heeft om de rekenkracht van het datawarehouse te definiëren.
Al met al is de prijsstelling van cloud datawarehouses behoorlijk complex. Deze complexiteit kan opzettelijk zijn om het buitengewoon moeilijk te maken om prijzen te vergelijken tussen verschillende datawarehouses. Neem bijvoorbeeld AWS Redshift, dat vijf verschillende prijsmodi biedt zonder de opslagkosten mee te rekenen. Om deze reden zullen we niet alle prijsopties in deze post verkennen, aangezien ze ook onderhevig zijn aan verandering.
In de serverloze modus betaal je voor elke byte die wordt verwerkt door de queries die je uitvoert in je datawarehouse. Veel datawarehouses zijn tegenwoordig ook ‘lake houses’, waardoor ze direct queries kunnen uitvoeren op je datameer (je opslagbuckets, zoals s3). Dit kan een geweldige (goedkope) optie zijn als je net begint en kleinere datasets hebt.
Het is van cruciaal belang om te erkennen dat niet alle cloudproviders het gewenste niveau van flexibiliteit bieden. AWS dient als een typisch voorbeeld, met name in hun databaseaanbod. Aan de onderkant is de kleinste beschikbare database de ‘dc2.large’ met 2 vCPUs. De volgende stap is echter de ‘dc2.8xlarge’, die maar liefst 18 keer duurder is. Laten we nu kijken naar de prijsmodellen, in detail, per oplossing.
Azure Synapse Analytics biedt twee prijsopties: serverless en dedicated. In de serverless modus betaalt u $5 per terabyte (TB) dataverwerking, terwijl de dedicated modus vooraf betaling vereist voor gereserveerde rekencapaciteit. Hier zijn verdere details:
BigQuery prijzen bestaan uit opslag- en rekenelementen. Hier is een overzicht:
Een van de sterke punten van BigQuery is dat het een aanzienlijk voordeel biedt met zijn serverloze architectuur, waardoor de noodzaak om instanties, groottes of VM’s handmatig te configureren wordt geëlimineerd. Het nadeel is natuurlijk dat je de flexibiliteit verliest om dit zelf af te stemmen.
Amazon Redshift prijzen bieden verschillende opties, waaronder on-demand instances, Redshift Serverless en Redshift Spectrum. Belangrijke details zijn onder meer:
uw opslag $25,60 per maand.
Redshift prijzen hebben zoveel componenten dat we het hier kort hebben gehouden. Bekijk de onderstaande voorbeeldvergelijkingen om een idee te krijgen.
Snowflake prijzen zijn gebaseerd op drie belangrijke componenten: opslagkosten per terabyte, de prijs voor het uitvoeren van virtuele warehouses in credits per uur, en het accounttype dat de creditprijs bepaalt. Hier is een overzicht:
Een snel overzicht van de belangrijkste prijsopties voor verschillende cloudproviders:
| Opslag (1TB) / Maand | Capaciteitsgebaseerde rekentarieven | Serverless rekentarieven | Opmerking | |
|---|---|---|---|---|
| Snowflake | $45 | $2,60 / credituur | - | Snowflake ondersteunt geen serverless-modus. |
| BigQuery | $20 | $0,044 / slotuur | $6 / TB | |
| Redshift | $25,60 | $0,324 / uur (dc2.large) | $5,00 / TB | |
| Azure Synapse Analytics | $23 | $1,51 / uur (DW100c) | $5 / TB |
Vervolgens vergelijken we de kosten voor het draaien van een typisch (klein formaat) cloud datawarehouse voor business intelligence-doeleinden. In deze vergelijking vergelijken we (zo representatief mogelijk) Snowflake, Redshift, Azure Synapse Analytics en Google BigQuery met de volgende kenmerken:
(We proberen zo nauwkeurig mogelijk te vergelijken; dit is niet altijd eenvoudig omdat niet elke provider uitlegt hoeveel vCPU’s of RAM u krijgt met hun getrapte modellen)
De onderstaande tabel toont de kosten voor het draaien van deze setup voor één maand per cloudprovider:
| Opslag (1TB) | Laadkosten | Gebruikskosten | Totaal | |
|---|---|---|---|---|
| Snowflake | $45 | $403 | $2080 | $3040,50 |
| BigQuery | $20 | Gratis | $281 | $301 |
| Redshift | $25,60 | $20,00 | $129,60 | $175.20 |
| Azure Synapse Analytics | $23 | Gratis | $302 | $325 |
In ons vorige voorbeeld keken we naar het draaien van ons datawarehouse gedurende ~26% van de tijd. Dit is een geweldige manier om geld te besparen indien van toepassing. Dit is echter niet altijd het geval: in veel situaties wilt u dat uw datawarehouse altijd actief is. Een voorbeeld hiervan kan een mobiele applicatie zijn met ingebouwde analytics en actieve gebruikers op elk moment van de dag. Dit zal uw kosten aanzienlijk verhogen.
Merk op dat onze vergelijkingen geen rekening houden met enkele van de meer complexe details bij het overwegen van de kosten van uw cloud datawarehouse, zoals kosten voor gegevensoverdracht. Bovendien zijn er ook verschillende manieren om uw kosten voor het cloud datawarehouse te optimaliseren, zoals het kopen van verplichtingen voor langere periodes.
Samengevat is het over het algemeen aanbevolen om bij het overwegen van de prijzen van datawarehouses te blijven bij het datawarehouse dat wordt geleverd door uw cloudprovider. Dit om tijd, geld te besparen en de complexiteit van gegevensmigratie tussen clouds te vermijden. Anders kan Snowflake worden ingezet in een van de clouds naar keuze, wat een marktleider is en zeker geschikt is voor enterprise ondernemingen, maar duurder is.
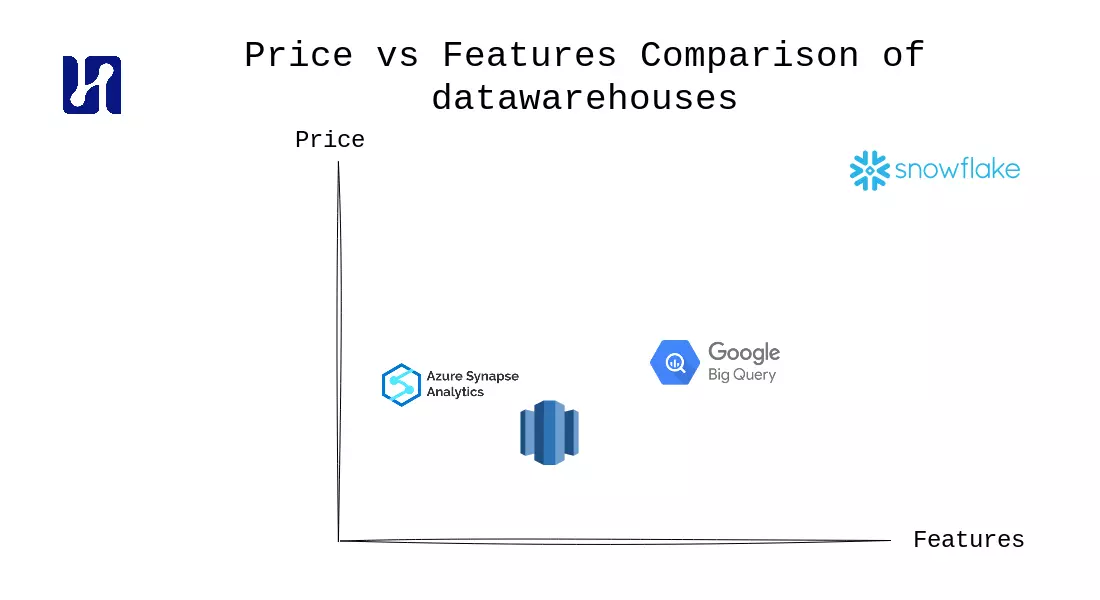
Onder de drie belangrijkste cloudproviders (exclusief Snowflake) valt BigQuery op als een prominente speler op het gebied van cloud datawarehouses. Het biedt unieke functies en is het vlaggenschipproduct van Google. Met name het rekentariefmodel van BigQuery biedt voordelen zoals flexibiliteit met on-demand prijzen voor kleine belastingen en dynamische toewijzing van slots. Deze flexibiliteit helpt kosten te optimaliseren en is in lijn met de serverless-belofte van de cloud. Daarnaast speelt BigQuery automatisch in op de behoefte om zowel kleine gelijktijdige query’s als incidentele zware query’s te verwerken, waardoor het een gebruiksvriendelijke keuze is.
Hoewel Snowflake oplossingen biedt zoals het pauzeren van datawarehouses, biedt het niet dezelfde mate van gemak en gebruiksvriendelijkheid als BigQuery. De toonaangevende positie van Snowflake in de branche en de focus op enterprise ondernemingen maken het een voorkeurskeuze in bepaalde scenario’s, maar voor de meeste gebruikers is het verstandig om gebruik te maken van de functies en voordelen van het datawarehouse dat wordt geleverd door hun cloudprovider.
Dit artikel zou niet compleet zijn zonder rekening te houden met de verschillende implementatieopties voor uw datawarehouse. In de praktijk is het vaak zinvol om gebruik te maken van de beschikbare cloudopties, maar het is zeker de moeite waard om de afwegingen te onderzoeken. Hieronder hebben we de belangrijkste afwegingen opgesomd voor het gebruik van een cloud datawarehouse:
1. Schaalbaarheid: Een belangrijk voordeel van cloud datawarehouses is hun vermogen om automatisch resources op- of af te schalen op basis van de vraag. Deze schaalbaarheid zorgt ervoor dat het datawarehouse verschillende workloads efficiënt kan verwerken zonder handmatige tussenkomst. In tegenstelling hiermee vereisen on-premise datawarehouses vaak voorafgaande capaciteitsplanning en resourceallocatie, wat kan leiden tot onderbenutting of prestatieproblemen tijdens piekperiodes.
2. Flexibele prijsstelling: Cloud datawarehouses bieden doorgaans flexibele prijsmodellen die aansluiten bij gebruikspatronen. Ze bieden vaak opties voor betalen naar gebruik of prijsstelling op basis van verbruik, waardoor organisaties hun kosten kunnen schalen op basis van daadwerkelijk gebruik. Deze flexibiliteit maakt betere kostenoptimalisatie mogelijk, vooral voor organisaties met fluctuerende workloads. Aan de andere kant vereisen on-premise datawarehouses aanzienlijke initiële investeringen in hardware, softwarelicenties en onderhoud, waardoor ze minder flexibel zijn bij veranderende zakelijke behoeften.
3. Duurder: Hoewel on-premise datawarehouses lagere initiële installatiekosten kunnen hebben, kunnen ze op de lange termijn duurder worden door hardware-upgrades, onderhoud en doorlopende operationele kosten. In tegenstelling hiermee elimineren cloud datawarehouses de behoefte aan hardware-aanschaf, infrastructuurbeheer en gerelateerde kosten. Het pay-as-you-go-model van cloud datawarehouses zorgt ervoor dat organisaties alleen betalen voor de resources die ze daadwerkelijk gebruiken, waardoor het een kosteneffectievere optie is voor veel bedrijven.
4. Volledig beheerd: Cloud datawarehouses zijn doorgaans volledig beheerde services die worden geleverd door cloudproviders. Dit betekent dat de cloudprovider zorgt voor infrastructuurvoorziening, software-updates, beveiliging en prestatieoptimalisatie. On-premise datawarehouses daarentegen vereisen toegewijde IT-teams om hardware, software-installaties, patches, upgrades en algemeen systeemonderhoud te beheren. De verantwoordelijkheid voor het beheer van de infrastructuur en het waarborgen van de beschikbaarheid ligt bij het IT-personeel van de organisatie.
5. Uptime-garanties: Cloud datawarehouses worden vaak geleverd met service level agreements (SLA’s) die een hoge beschikbaarheid en uptime garanderen. Cloudproviders investeren in robuuste infrastructuur en redundantie om de downtime tot een minimum te beperken. In tegenstelling hiermee zijn on-premise datawarehouses afhankelijk van de IT-infrastructuur van de organisatie, en worden de risico’s van downtime voornamelijk beheerd door de organisatie zelf. Het realiseren van een hoge beschikbaarheid in on-premise omgevingen vereist vaak aanzienlijke investeringen in redundante hardware, failover-systemen en rampenherstelplannen.
6. Eigen software: Cloud datawarehouses maken doorgaans gebruik van eigen software die is ontwikkeld door de cloudprovider. Deze oplossingen zijn specifiek ontworpen om optimaal gebruik te maken van de cloudinfrastructuur en bieden geoptimaliseerde prestaties, schaalbaarheid en beveiliging. On-premise datawarehouses kunnen daarentegen gebruikmaken van een combinatie van commerciële en open-source software, waardoor organisaties integratie, compatibiliteit en mogelijke licentiekosten moeten beheren.
Over het algemeen bieden cloud datawarehouses voordelen zoals schaalbaarheid, flexibele prijsstelling, beheerde services, uptime-garanties en eigen software die de bedrijfsvoering stroomlijnen en kostenbesparingen opleveren. Organisaties moeten echter hun specifieke vereisten, nalevingsbehoeften, zorgen over gegevenssoevereiniteit en langetermijnkosten evalueren voordat ze kiezen tussen cloud- en on-premise datawarehouses.
Datawarehouses spelen een cruciale rol in de datagedreven wereld van vandaag, waarin organisaties de infrastructuur nodig hebben om grote hoeveelheden gegevens op te slaan, te beheren en te analyseren. Door gegevens uit verschillende bronnen te consolideren tot één bron van waarheid, stellen datawarehouses organisaties in staat om krachtige analysemogelijkheden, historische analyses, trendidentificatie en self-service business intelligence te bieden. Ze stellen organisaties in staat om op gegevens gebaseerde beslissingen te nemen, operationele efficiëntie te optimaliseren, klantgedrag te begrijpen en het volledige potentieel van AI te benutten.
De architectuur van datawarehouses omvat het scheiden van rekencapaciteit en opslag, het gebruik van een centrale locatie voor gegevensopslag en het implementeren van processen voor gegevensreiniging en modellering om de kwaliteit van de gegevens te verbeteren. Het gebruik van ELT (Extract, Load, Transform)-methodologieën en tools zoals dbt vereenvoudigt het proces van gegevensextractie, -laden en -transformatie, waardoor efficiënte gegevensintegratie en -transformatie binnen het datawarehouse mogelijk worden.
Bij het overwegen van datawarehouses is het belangrijk om de prijsopties te evalueren die worden aangeboden door verschillende cloudproviders. Capaciteitsgebaseerde prijzen en prijsmodellen voor serverloze berekening worden veel gebruikt, waarbij elke optie zijn eigen voordelen en overwegingen heeft. Azure Synapse Analytics, Google BigQuery en Amazon Redshift zijn populaire datawarehouse-oplossingen, elk met zijn eigen prijsstructuur en functies.
Al met al stellen datawarehouses organisaties in staat om de kracht van gegevens te benutten, bruikbare inzichten te verkrijgen en zakelijk succes te stimuleren in de datagedreven wereld van vandaag. Door te investeren in een robuuste datawarehouse-infrastructuur en het volgen van best practices kunnen bedrijven het ware potentieel van hun gegevens benutten en voorop blijven lopen in een competitieve markt.

Maximilian is een liefhebber van machine learning, ervaren data-engineer en mede-oprichter van BiteStreams. In zijn vrije tijd luistert hij naar elektronische muziek en houdt hij zich bezig met fotografie.
Read moreEnjoyed reading this post? Check out our other articles.
Maximilian Filtenborg
 Maximilian Filtenborg
Maximilian Filtenborg
 Donny Peeters
Donny Peeters
Wordt meer datagedreven met BiteStreams en laat de concurrentie achter je.
Contact us