 Maximilian Filtenborg
Maximilian Filtenborg
In deze blog beschrijven we hoe je je eigen Dagster IO managers kunt bouwen en gebruiken, met AWS Redshift als voorbeeld. We gaan dieper in op de basisprincipes van IO managers, en de tips en trucs die we hebben geleerd bij het bouwen van verschillende IO managers in de loop van de tijd.
Van de IO manager documentatie van Dagster:
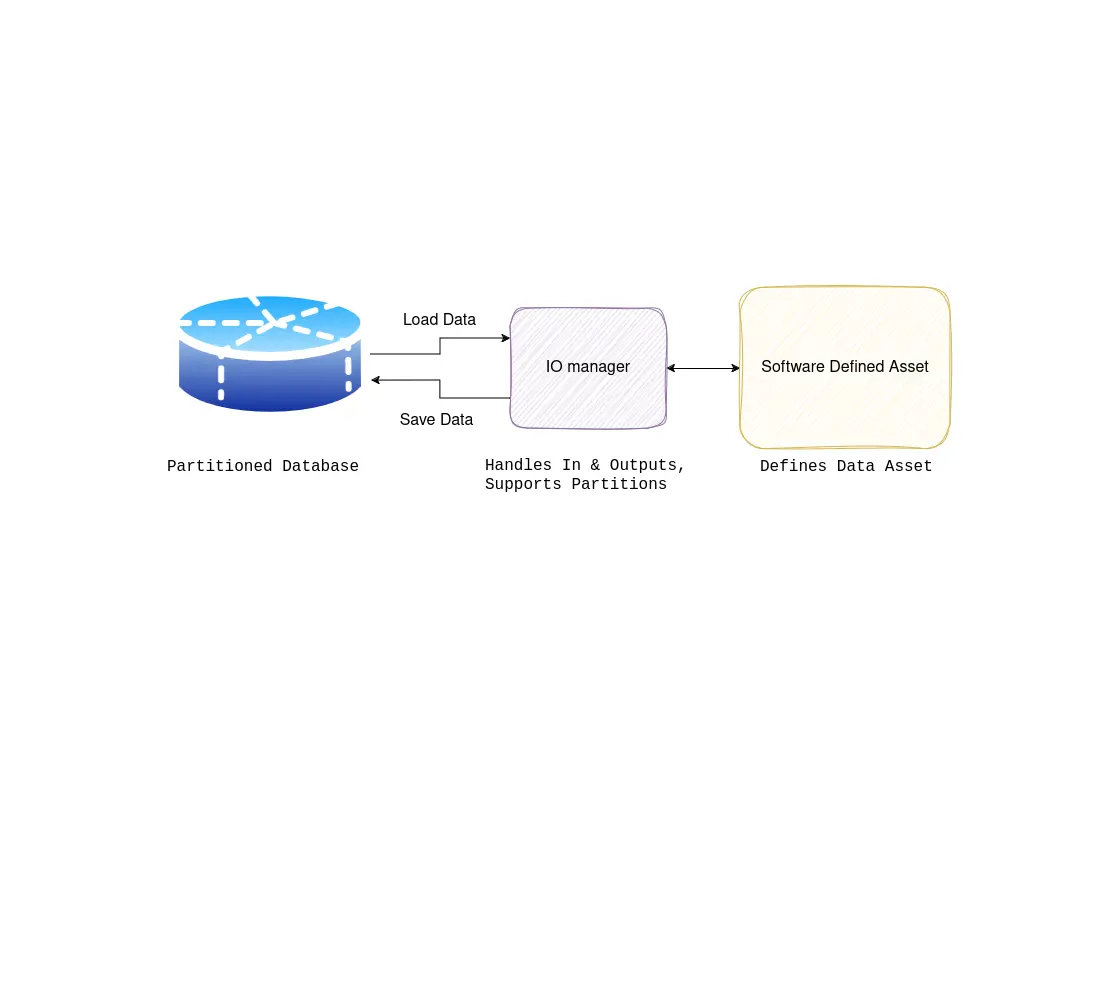
I/O managers are user-provided objects that store asset and op outputs and load them as inputs to downstream assets and ops. They can be a powerful tool that reduces boilerplate code and easily changes where your data is stored.
IO managers, gecombineerd met partitities, zijn een van de krachtigste concepten in Dagster; in wezen stellen ze je in staat om te voorkomen dat je code opnieuw moet schrijven om data van verschillende bronnen, vaak je database naar keuze, te laden en op te slaan. Dit is enorm krachtig als je je realiseert dat veel van je code alleen maar data leest en schrijft naar databases, bestandopslag, enz. Het interessante deel van je code zijn de transformaties die je op de data uitvoert; het laden en ophalen van data is noodzakelijk maar voegt niet veel waarde toe. Om deze reden is het altijd goed om te overwegen of een IO manager een geschikte oplossing is voor je huidige ETL uitdagingen.
Als alles wat je hebt een hamer is, ziet alles eruit als een spijker.
Elke programmeur heeft dit meegemaakt, een goed voorbeeld hiervan is de RDBMS. Zoals met elke abstractie, werkt het geweldig totdat het dat niet doet. De Dagster IO manager is slechts een hulpmiddel in je gereedschapskist, en als het niet past bij het probleem dat je hebt, moet je het niet gebruiken.
De IO manager is zeer geschikt als je een abstract patroon volgt van data inladen, data transformeren, en data opslaan. Als dit niet het abstracte patroon van je probleem is, kan de IO manager niet veel hulp bieden.
Als je workflow bijvoorbeeld complexe datatransformaties omvat die niet netjes passen in het input-verwerkings-output model dat door de IO manager wordt ondersteund, kan het proberen om het in dat framework te dwingen leiden tot omslachtige en inefficiënte code. In dergelijke gevallen is het beter om een stap terug te doen en te evalueren of het gebruik van de IO manager overeenkomt met de natuurlijke stroom van je probleem of dat een andere benadering geschikter zou zijn.
Uiteindelijk houdt de keuze van het juiste gereedschap voor de taak in dat je het probleemgebied begrijpt, rekening houdt met de specifieke vereisten en beperkingen, en bereid bent om aan te passen en alternatieve oplossingen te verkennen wanneer dat nodig is. De Dagster IO manager is een waardevol hulpmiddel in je gereedschapskist, maar het is belangrijk om te herkennen wanneer het het juiste hulpmiddel is voor de taak en wanneer een andere aanpak geschikter zou zijn.
Voordat we ingaan op de implementatiedetails van een IO manager, laten we eerst enkele best practices en tips voor het effectief ontwikkelen en gebruiken van IO managers belichten. In deze sectie hebben we geprobeerd de belangrijkste punten te noteren.
Error handling is een van de meer complexe zaken in software, het voordeel van de IO manager is dat je dit maar een keer hoeft te implementeren. Implementeer robuuste mechanismen voor foutenafhandeling binnen je IO manager om storingen gracieus te verwerken en te herstellen van fouten. Dit omvat het omgaan met netwerkproblemen, authenticatiefouten en datainconsistenties om de betrouwbaarheid van je datastromen te waarborgen.
Automatiseer de creatie van schemas binnen je IO manager waar mogelijk. Dit stroomlijnt dataopslag, vermindert fouten en zorgt voor consistentie in de data. Dynamische schema generatie op basis van data of sjablonen verbetert schaalbaarheid en aanpassingsvermogen, en optimaliseert de efficiëntie van Dagster-pijplijnen. Overweeg ook wat er gebeurt als het schema in de database niet overeenkomt met het schema van de data; het is een goed idee om in dit geval een fout te genereren.
Het implementeren van idempotentie met behulp van Dagster partitionering voegt een extra laag betrouwbaarheid toe aan je dataprocessen. Door je data op te splitsen in afzonderlijke segmenten op basis van bepaalde criteria (zoals tijdsintervallen of gegevensbronnen), creëer je een gestructureerde aanpak voor het omgaan met herhalingen en fouten. Elke partitie vertegenwoordigt een zelfvoorzienende eenheid van werk, waardoor het gemakkelijker wordt om dataverwerkingstaken bij te houden en te beheren. Als er iets misgaat tijdens de verwerking, kun je individuele partities opnieuw proberen zonder de andere te beïnvloeden, wat zorgt voor consistente resultaten in je pijplijn. Het gebruik van Dagster partitionering in combinatie met idempotente logica versterkt de integriteit van je dataprocessen, en minimaliseert het risico op fouten en inconsistenties. Dit is vrijwel een must-have.
Optimaliseer de prestaties van je IO manager door de latency te minimaliseren en de doorvoer te maximaliseren. Dit omvat het optimaliseren van datatransfermechanismen, het benutten van caching strategieën en het parallelliseren van dataverwerkingen waar mogelijk om de algehele efficiëntie van de pijplijn te verbeteren. Concrete strategieën zijn het batchen van je operaties, het gelijktijdig of parallel uitvoeren van werk, en het cachen van zware operaties.
Ontwerp je aangepaste IO manager met herbruikbaarheid en modulariteit in gedachten. Overweeg om gemeenschappelijke functionaliteit te abstraheren in herbruikbare componenten of bibliotheken om de integratie in meerdere pijplijnen en projecten te vergemakkelijken.
Nu we de basis hebben gelegd voor hoe een IO manager eruit zou moeten zien, laten we nu kijken naar een praktisch voorbeeld van hoe je een IO manager opzet.
In deze sectie gaan we een aangepaste IO manager voor Redshift implementeren, de datawarehouse oplossing van Amazon Web Services (AWS). We richten ons op het opslaan van gegevens naar Redshift binnen Dagster-pijplijnen. De custom IO manager die we zullen ontwikkelen, zal het beheer van schema’s, dataopslag en partitiemanagement afhandelen en een uitgebreide oplossing bieden voor interactie met Redshift-databases binnen Dagster-workflows. De in- en outputtypen van deze IO manager zijn pandas, een van de meest gebruikte python packages. Voor betere prestaties raden we aan om andere packages te gebruiken zoals pyarrow of polars.
Onze Redshift IO manager zal de kloof overbruggen tussen Dagster-pijplijnen en een Redshift-cluster, en de verplaatsing van data tussen deze omgevingen vergemakkelijken. Deze custom IO manager zal gebruik maken van AWS S3, waardoor we data zo efficiënt mogelijk kunnen opslaan.
De belangrijkste functionaliteiten van onze Redshift IO manager omvatten:
Om onze RedshiftPandasIOManager te initialiseren, hebben we de volgende definitie:
class RedshiftPandasIOManager(ConfigurableIOManager):
region_name: str
cluster_identifier: str
user: str
database: str
host: str
port: str
s3_iam_role: str
bucket_name: strOm de Redshift Pandas IO manager in te stellen, moet je AWS-referenties, Redshift-clusterdetails en S3-bucketconfiguraties opgeven. Initialiseer de IO manager als volgt:
from dagster import Definitions
resources = {
"io_manager": RedshiftPandasIOManager(
host=EnvVar("AWS_REDSHIFT_HOST"),
database=EnvVar("AWS_REDSHIFT_DATABASE"),
port=EnvVar("AWS_REDSHIFT_PORT"),
user=EnvVar("AWS_REDSHIFT_USER"),
cluster_identifier=EnvVar("AWS_REDSHIFT_CLUSTER_IDENTIFIER"),
region_name=EnvVar("AWS_REDSHIFT_REGION_NAME"),
s3_iam_role=EnvVar("AWS_REDSHIFT_S3_IAM_ROLE"),
bucket_name=EnvVar("AWS_REDSHIFT_BUCKET_NAME"),
),
}
defs = Definitions(
assets=all_assets,
resources=resources,
# ...
)Wanneer deze wordt opgegeven als de io_manager in het resources dict van je Dagster Definitions object, zal deze standaard worden gebruikt voor al je assets.
Schemabeheer is cruciaal voor het handhaven van afstemming tussen Redshift-databases en de verwerkte data. De Redshift IO manager automatiseert schema creatie en tabelstructuurdefinities om database-interacties te stroomlijnen.
Onze functionaliteit voor schemabeheer omvat:
Laten we de implementatie binnen RedshiftPandasIOManager verkennen:
create_schemas Methode: Deze methode legt een verbinding met Redshift en voert SQL-query’s uit om schema’s en tabellen te creëren. De tabelstructuur wordt gedefinieerd op basis van de kolomtypen die uit de input data worden gehaald.def create_schemas(self,
context: "OutputContext",
columns_with_types: dict[str, str],
full_table_name: str,
partition_key: Optional[str],
schema: str):
context.log.debug(f"creating db-schemas for {schema=} {full_table_name=} {partition_key=}")
with (
self.get_connection() as connection,
connection.cursor() as cursor
):
try:
cursor.execute(f"CREATE SCHEMA IF NOT EXISTS {schema}")
schema_string_components = map(lambda x: f"\"{x[0].upper()}\" {x[1]}", columns_with_types.items())
schema_string = ", ".join(schema_string_components)
cursor.execute(f"CREATE TABLE IF NOT EXISTS {full_table_name} ({schema_string})")
connection.commit()
except Exception as e:
connection.rollback()
raise Failure(
description=f"Failed to create table {full_table_name} in Redshift"
f"for asset_key {context.asset_key} and partition "
f"key {partition_key}",
metadata=dict(
asset_key=context.asset_key,
partition_key=partition_key,
table_name=full_table_name,
error=str(e)
),
allow_retries=False
)_get_table_structure Functie: Deze hulpfunctie analyseert de structuur van de input data en retourneert een dict dat kolomnamen aan hun respectieve datatypes koppelt.
def _get_table_structure(df: pd.DataFrame) -> dict[str, str]:
columns = list(df.columns)
return {column: "VARCHAR(10000)" for column in columns}Automatisering van schemabeheer zorgt ervoor dat de database klaar is voor gegevensinvoer, en ervoor zorgt dat de input data compatibel zijn met het databaseschema.
Vervolgens gaan we dieper in op het efficiënt opschonen en opslaan van gegevens uit Pandas DataFrames in Redshift-tabellen.
De belangrijkste functionaliteit van de Redshift IO manager is het efficiënt opslaan van gegevens uit Pandas DataFrames in Redshift-tabellen. Dit proces zorgt ervoor dat gegevens met integriteit en consistentie in Redshift worden ingevoerd, klaar voor analyse en verdere verwerking.
Het opslaan van gegevens omvat verschillende belangrijke stappen:
Laten we de implementatie van de functionaliteit voor het opslaan van gegevens binnen onze RedshiftPandasIOManager-klasse verkennen:
handle_output Methode: Deze methode is verantwoordelijk voor het verwerken van de uitvoergegevens en het initiëren van het proces om deze in Redshift op te slaan. Binnen deze methode:
upload_data_to_s3-methode._get_table_structure-functie.create_schemas-methode.save_data-methode.save_data Methode: Deze methode voert SQL-query’s uit om bestaande gegevens te verwijderen (indien van toepassing) en de nieuwe gegevens van Amazon S3 naar de Redshift-tabel te kopiëren. Het behandelt zowel volledige tabelverversingen als partitie-updates. Zo werkt de methode:def handle_output(self, context: "OutputContext", obj: pd.DataFrame) -> None:
if obj is None or len(obj) == 0:
context.log.info(
f"{self.__class__.__name__} skipping handle_output: The asset "
f"{context.asset_key} does not output any data to store (the "
f"asset may store the result during the operation.")
return
schema = "_".join(context.asset_key.path[:-1])
table_name = context.asset_key.path[-1]
full_table_name = f"{schema}.{table_name}"
partition_key = None
if context.has_asset_partitions:
try:
partition_key = context.asset_partition_key
except CheckError as e:
raise Failure(
description=f"{self.__class__.__name__} does not support partition key ranges",
metadata=dict(
asset_key=context.asset_key
),
allow_retries=False
)
partition_expr = context.metadata.get("partition_expr")
if partition_expr is None and partition_key is not None:
raise Failure(
description=f"Asset has partition key, but no partition_expr in its metadata",
metadata=dict(
asset_key=context.asset_key,
partition_key=partition_key,
),
allow_retries=False
)
context.log.info(f"Starting process to store output of asset "
f"{context.asset_key} and partition key {partition_key} in Redshift")
s3_object_name = self.upload_data_to_s3(full_table_name, obj, partition_key)
columns_with_types = _get_table_structure(obj)
context.log.info(f"Loaded {len(obj)=} for {context.asset_key} and {partition_key=} records to disk."
f" Preparing to load these into redshift.")
self.create_schemas(context, columns_with_types, full_table_name, partition_key, schema)
self.save_data(context, s3_object_name, full_table_name, partition_expr, partition_key)
def save_data(self,
context: "OutputContext",
s3_object_name: str,
full_table_name: str,
partition_expr: str,
partition_key: Optional[str]):
context.log.debug(f"saving data for {full_table_name=} {partition_key=}")
with (
self.get_connection() as connection,
connection.cursor() as cursor
):
try:
# First clear the partition or table out.
if partition_key is None:
# Do a full refresh, and delete all data
context.log.debug(f"Fully clearing table {full_table_name} since no partition key is given")
query = f"DELETE FROM {full_table_name}"
cursor.execute(query)
else:
# Try to remove the old partition data and load the new data
context.log.debug(f"Clearing partition such that {partition_expr} = {partition_key}"
f" for table {full_table_name}")
query = f"DELETE FROM {full_table_name} WHERE {partition_expr} = %s"
cursor.execute(query, (partition_key,))
# Copy all the file starting with `s3_url_prefix` to the table `table_name`.
# The role `self.s3_iam_role is used by Redshift to authenticate to S3
# The parameter EMPTYASNULL ensures that empty strings in the csv are stored as NULL in Redshift
s3_url_prefix = f"s3://{self.bucket_name}/{s3_object_name}"
query = f"COPY {full_table_name} FROM '{s3_url_prefix}' IAM_ROLE '{self.s3_iam_role}' CSV gzip EMPTYASNULL"
cursor.execute(query)
connection.commit()
except Exception as e:
# Abort execution of the operation
connection.rollback()
raise Failure(
description=f"Failed to store data in Redshift for asset_key {context.asset_key} "
f"and partition key {partition_key}",
metadata=dict(
asset_key=context.asset_key,
partition_key=partition_key,
table_name=full_table_name,
error=str(e)
),
allow_retries=False
)In deze methode behandelen we het verwijderen van bestaande gegevens voordat we nieuwe gegevens laden. Dit zorgt ervoor dat de Redshift-tabel wordt bijgewerkt met de meest recente informatie, waardoor de gegevensintegriteit behouden blijft.
upload_data_to_s3 Methode: Deze methode uploadt de uitvoergegevens in CSV-formaat (gecomprimeerd) naar Amazon S3, ter voorbereiding op het laden in Redshift. def upload_data_to_s3(self, full_table_name, obj, partition_key):
buf = BytesIO()
obj.to_csv(buf, index=False, header=False, compression='gzip')
s3_object_name = f"{full_table_name}/{partition_key}.csv.gzip"
client = boto3.client("s3")
client.put_object(
Body=buf,
Bucket=self.bucket_name,
Key=s3_object_name,
)
return s3_object_nameDoor efficiënte gegevensopslagmechanismen te implementeren, zorgt onze Redshift IO manager ervoor dat gegevens naadloos worden geïntegreerd in Redshift voor analyse en verwerking binnen Dagster-pijplijnen.
Om de reikwijdte van deze blog enigszins eenvoudig te houden, hebben we niet alle toeters en bellen opgenomen die je misschien zou willen hebben. Mogelijke verbeteringen aan de IO manager kunnen de volgende zijn:
COPY-commando; het splitsen van deze bestanden in ongeveer 100 MB grote bestanden versnelt het laden van de gegevens en voorkomt fouten in Redshift.De volledige code voor de IO manager is hier te vinden: Dagster Redshift IO manager
In deze blog hebben we de basisprincipes van Dagster IO managers verkend en het proces van het bouwen van een aangepaste IO manager voor AWS Redshift onderzocht. Door een diepgaande analyse van elke stap, van schemabeheer tot gegevensopslag, hebben we inzicht gegeven in best practices en tips voor het ontwikkelen van robuuste en efficiënte IO managers.
Vooruitkijkend zijn er tal van mogelijkheden voor verdere verbeteringen en optimalisaties aan onze Redshift IO manager, zoals het ondersteunen van key ranges, het optimaliseren van gegevensformaten en laadstrategieën, en het verbeteren van prestaties en schaalbaarheid.
Samenvattend zijn Dagster IO managers een krachtig hulpmiddel voor het vereenvoudigen van de ontwikkeling en het beheer van gegevenspijplijnen, en bieden ze flexibiliteit, modulariteit en betrouwbaarheid. Door de kernprincipes en best practices te begrijpen die in deze blog zijn uiteengezet, hebben data-engineers een robuuste basis om hun eigen IO managers te ontwikkelen.

Maximilian is een machine learning enthousiasteling, ervaren data engineer en medeoprichter van BiteStreams. In zijn vrije tijd luistert hij naar elektronische muziek en houdt hij van fotografie.
Lees meerEnjoyed reading this post? Check out our other articles.
Maximilian Filtenborg
 Maximilian Filtenborg
Maximilian Filtenborg
 Maximilian Filtenborg
Maximilian Filtenborg